In this post I will show you how a proper documentation and templates with meaning could help to reduce the technical debt in your team or company.
Technical Debt
Probably you know what is technical debt. If not, you could research to talk properly. I hope these images could help you to know if your team or company has technical debt:

Basically if, to add a new simple feature or fix a bug by a old team member (which knows everything about project), takes long, you have some kind of technical debt
Technical debt is money

If you are boring about another technical debt lecture, this will wake you up:
A classic example of technical debt is the Year 2000 problem. Many software developers in the 1960s and 1970s chose to save precious memory by storing dates as two digits: “73” instead of “1973.” The practice continued for years, even as memory prices declined. Many of those programs became embedded into the operational business and stayed in use far longer than anyone had expected. As the year 2000 approached, thousands of businesses and government agencies realized that date calculations would fail at a massive scale and so undertook a frenzied clean-up effort. Addressing the Y2K problem is estimated to have cost $100 billion. Source: Examples of technical debt
A more close example could be how much are you paying to a software developer multiplied by how many hours takes to add a new feature or fix a bug.
Not always in technical debt is about code
If you read about technical debt, almost all lectures point us to code refactoring. Code refactoring is one of the corner stone in software development but, in technical debt there are other causes:
- User without proper defined process
- Poor management
- Deficient skills
- Software stages undocumented or human centralized knowledge

In this post I will cover how to fight against technical debt with documentation practices
How to discover what documentation you need
There are not a standard or methodology to document software. UML is so dense and I think is one of the culprits that nobody likes to document. Like hybrid agile methodologies in which you combines what you need from scrum, kanban, etc, to document a software you could choose some UML diagrams and a little common sense.
Also in your tech stack you could have several software types:
- library
- monolith
- microservice
- web forms
- mobile forms
- schedulers
- e2e tests
- integrations
The following questions helped me to create documentation templates and to explain them to my coworkers:
- Where is the source code?
- Who require the feature?
- Who led the software team?
- Who developed the feature?
- In which language are based the software?
- How can I start the application in my local workstation?
- If it stated correctly, how can I test it, what is the form url / api endpoint?
- What the software does in terms of flow decisions, logical or conditionals?
- How I deploy it to the test environment? Is i manual or automated process?
- Where is the log stored in case of support?
- What kind of security is used?
- How configuration are managed? I mean yaml or properties between environments like test and production.
- etc
If you are a developer, just point in the side of a new developer in your team:
What would help you to understand the source code without reading the source code?
How to NOT address the knowledge transfer
A common practice to address that question by good people is the explanation of some veteran to explain you everything in a marathon session (hours).
In other cases without luck, the new developer should review the code and understand everything by himself
How to address the knowledge transfer
Some boss told me nobody is indispensable and from a manager or ceo point of view, that makes sense because if nothing is documented and all the knowledge is centralized in a few employees, that can generate vices, conceit or worse: What happen if that employee leaves the company without a proper knowledge transfer.
From a coworker point, if the men/women with all the not shared knowledge (years) leaves the company in good or on bad terms, that will be traduced in stressed hours because no matter what, he will have to solve it. Usually this adds more technical debt
Also this could affect to the production support team.

Preliminary advice
If you reach this point, I can say that you understand and or have technical debt. So my main advices are
- To focus or split the documentation in the features. Nobody likes to read a pdf with 200 pages :/
- Like a zoom in, zoom out, the documentation should be atomic and fine grained to help an to have an easy learning
- Assign a kind of unique id to each feature to be documented. Not numeric because handle a sequence is complicated
- Start the documentation from what is visible like a web , desktop or mobile form. From that point everything begins: logic, conditional, integrations, apis, security, etc
In the following section I will show you some of my own documentation topics. This could be documented at the frontend and backend layer. It all depends on how deep or detailed you want to be
High Level Layered Diagram
This diagram shows at high level the layers and cross-cutting services of the entire architecture.
As a summary, the diagram should look like this:

I will deepen on this in next posts
Request Driven Integration Diagram
This diagram is aimed to show the direct relationship between the artifacts of components more important of the solution.
In P2P (point to point) integration, the systems exclusively know about each other, the data models, the capabilities, and all the technology infrastructure that each application is supporting to enable that integration. The two systems are therefore what we would deem “tightly coupled.” If there were only a small number of applications, this would be fine. But as the number of tight couplings grows, the infrastructure becomes brittle, prone to failure, and difficult to maintain. Source: ESB vs P2P: Why It’s Finally Time to Ditch P2P. Source: https://www.talend.com/resources/esb-vs-p2p/


Infrastructure Deployment & Networking Diagram
This diagram shows us in a simple way the location of the applications on the infrastructure, indicating data such as ips, routes, firewalls, vpn, ports, cloud zones, etc.

Security Diagram
How the security works: oauth1, oauth2 , openId, CAAS, IAM, etc

Internal Architecture
How the microservice works

How the web works
Base Url

Authentication & Authorization
How the login and roles are handled or required
Api Specification
All decent api should have a wiki like this: https://api.sirena.app/

In which any endpoint and its parameters should be explained
You could use my template : https://github.com/usil/docs-template-rest-api
Technologies
A simple list of languages, frameworks, etc

Source: https://www.infolob.com/full-stack-open-source-software/
Developer Workspace
Everything required to start in developer mode this application by a human developer who is not the author of this application.
Global and First Level dependencies
List all the global dependencies required for the entire api or microservice like: ftp, sftp, internals apis, third parties apis, databases, azure face recognition, google drive, paypal, etc
Environment Variables
How configurations are managed, especially for multiple environments like dev, test and prod.
Twelve Factor adive us that an app’s environment-specific configuration should be stored in environment variables at oerativ system level, not in the app’s source code. Source: https://12factor.net/config

Build
How artifacts are built: manually with IDE, manually with shell, docker
Deploy
How artifacts are deployed: manually with IDE, manually with shell, docker, kubernetes, heroku, aws, gcp, etc
Required configurations
List the global configurations required to run this api on any environment. Specific configuration should be explained at rest endpoint level. Specific endpoint dependencies, should be showed at the endpoint level
Dev/testing/prod parity
What measures are taken to ensure that the environment where the application is developed or tested has the same characteristics as the production environment. Example: Developer codes on Windows 7 but the test environment is over Ubuntu and production is on Centos
Logging
How the log is managed and or stored.
Exception handling
Exception handling is the process of responding to unwanted or unexpected events when a computer program runs. Exception handling deals with these events to avoid the program or system crashing, and without this process, exceptions would disrupt the normal operation of a program. Source: https://www.techtarget.com/searchsoftwarequality/definition/error-handling
It’s not ok to handle exceptions in an ad-hoc way. Exception handling should be a system wide concern. That means catching an exception, arbitrarily logging it before rethrowing isn’t a good idea. We should be carefully considering when and how to handle exceptions. With a high level strategy, things just become easier. You focus exception handling to just a few places making it easy to test and easy to apply consistently. Source: http://baddotrobot.com/blog/2012/03/28/exception-handling-as-a-system-wide-concern/
Audit
How audit is handled
Internationalization (I18N)
Internationalization (sometimes shortened to “I18N , meaning “I - eighteen letters -N”) is the process of planning and implementing products and services so that they can easily be adapted to specific local languages and cultures, a process called localization . The internationalization process is sometimes called translation or localization enablement. Source: https://www.techtarget.com/whatis/definition/internationalization-I18N
Concurrency (multi-threading)
Concurrency is the ability to run several programs or several parts of a program in parallel. If a time consuming task can be performed asynchronously or in parallel, this improves the throughput and the interactivity of the program. Source: https://www.vogella.com/tutorials/JavaConcurrency/article.html
Multi-threaded programs may often come to a situation where multiple threads try to access the same resources and finally produce erroneous and unforeseen results. Source: https://www.geeksforgeeks.org/synchronization-in-java/
Example: https://docs.oracle.com/javase/tutorial/essential/concurrency/syncmeth.html
Block and Non-Blocking
In computer programming, synchronous and asynchronous models are essential. The terms offer a clue about what each programming model does and the differences between them. Synchronous tasks happen in order — you must finish task one before moving on to the next. Asynchronous tasks can be executed in any order, or even simultaneously. Sources:
- https://www.mendix.com/blog/asynchronous-vs-synchronous-programming
- https://www.trio.dev/blog/synchronous-and-asynchronous
Scalability
Scalability describes a system’s elasticity. While we often use it to refer to a system’s ability to grow, it is not exclusive to this definition. We can scale down, scale up, and scale out accordingly.
If you are running a website, web service, or application, its success hinges on the amount of network traffic it receives. It is common to underestimate just how much traffic your system will incur, especially in the early stages. This could result in a crashed server and/or a decline in your service quality.
Thus, scalability describes your system’s ability to adapt to change and demand. Good scalability protects you from future downtime and ensures the quality of your service. Source: https://www.cloudzero.com/blog/horizontal-vs-vertical-scaling
Caching
In computing, a cache is a high-speed data storage layer which stores a subset of data, typically transient in nature, so that future requests for that data are served up faster than is possible by accessing the data’s primary storage location. Source: https://aws.amazon.com/caching/
User guide or manual
All we know what is this :)
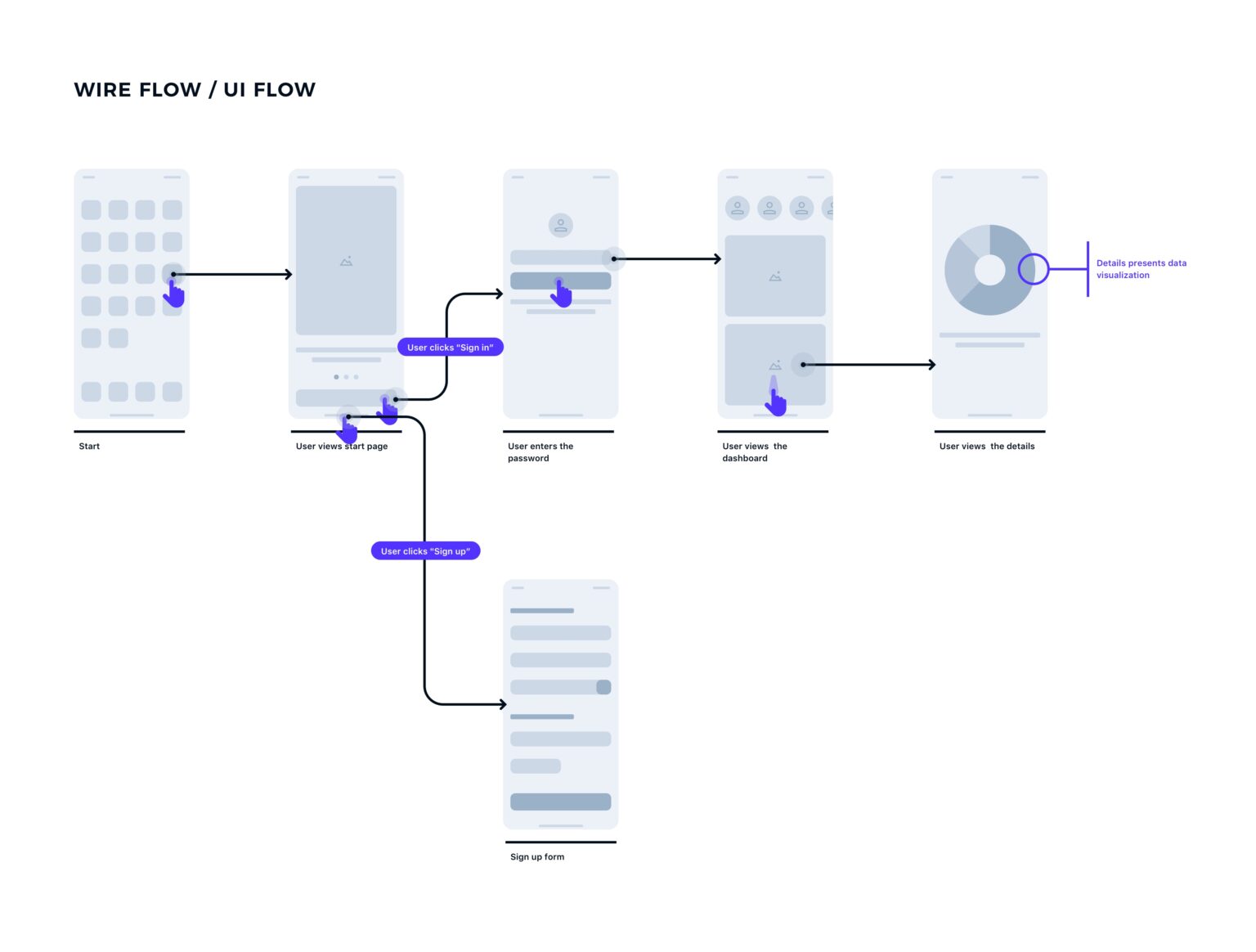
User UI Flow or Sitemap
Simple steps or flow to reah the form. A kind of summary of the user guide.
Flow Chart
Describes the logic and or steps of the algorithm used in the frontend. Starts with user and ends with a submit or any interaction with the backend services.

User Stories
User stories related to this specific feature

Business Rules
Related to this specific feature

source: https://www.bptrends.com/business-rule-solutions-obligations-are-business-rules/
Test Cases
Relates to quality assurance of this specific feature
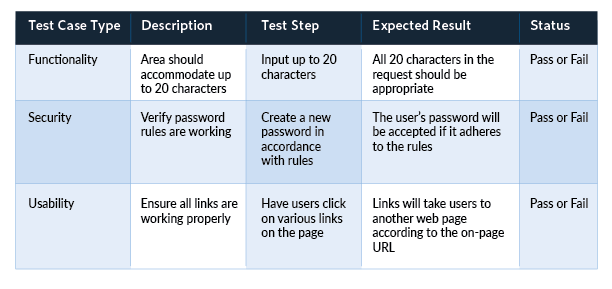
Source: https://www.parasoft.com/blog/how-to-write-test-cases-for-software-examples-tutorial/
Troubleshooting
Troubleshooting is a systematic approach to solving a problem. The goal of troubleshooting is to determine why something does not work as expected and explain how to resolve the problem. The first step in the troubleshooting process is to describe the problem completely. Problem descriptions help you and IBM® Software Support know where to start to find the cause of the problem. This step includes asking yourself basic questions:
- What are the symptoms of the problem?
- Where does the problem occur?
- When does the problem occur?
- Under which conditions does the problem occur?
- Can the problem be reproduced?
The answers to these questions typically lead to a good description of the problem, and that is the best way to start down the path of problem resolution.
Source: https://www.ibm.com/docs/en/om-jvm/5.4.0?topic=support-introduction-troubleshooting
Direct Dependencies
Dependencies that have direct impact on the operation of the service. First level should be in the table and second level just in the diagram.

Source code
and location of the package, folder, etc. showing where the files of this feature are

Sequence Diagram
This diagram represents the interaction between objects, components, artifact, etc over a specific period of time. In other words, it represents the sequence of messages flowing from one object to another. Starts with user and ends with a submit or any interaction with the backend.

Data model
Only if it is a monolithic application. If it is a modern spa web, this information should be found on the developer center section of each direct dependency

Lecture and image References
- https://twitter.com/petergyang/status/1575289122364608513
- https://www.reddit.com/r/ProgrammerHumor/comments/g39h75/what_technical_debt_looks_like/
- https://www.pinterest.com/pin/318348267411969397/
- https://amgrade.com/technical-debt-what-can-it-mean-for-startup/
- https://www.mendix.com/blog/what-is-technical-debt/
- https://innov8.place/what-is-user-flow/
- https://uxmisfit.com/2020/08/17/what-is-a-user-flow-everything-you-need-to-know/
- https://www.researchgate.net/figure/Sequence-diagram-of-a-testing-procedure-for-multi-tenancy-defects_fig6_309458801
- https://www.bptrends.com/business-rule-solutions-obligations-are-business-rules/
Coming soon
If I receive some claps:
- I will share a complete github repository ready to clone and customize using my own framework: https://github.com/docs4all/docs4all-demo
- I will post about architecture diagrams
- I will share templates in Plantuml https://plantuml.com/ which is a good option to diagram instead Visio or dekstop apps.
Conclusion
Documentation is time, no matter what but if there is in the mindset instead of a final task in the project, it will reduce the technical debt because, the new developer, the production support or any coworker could understand any of your solution features or bugs in a short time and without a senior explanation. Time is money $$$ in this world.
Until the next,
JRichardsz